Hi, I’m
Kieran Huggins
Director, R
&
D at
Universe
Projects
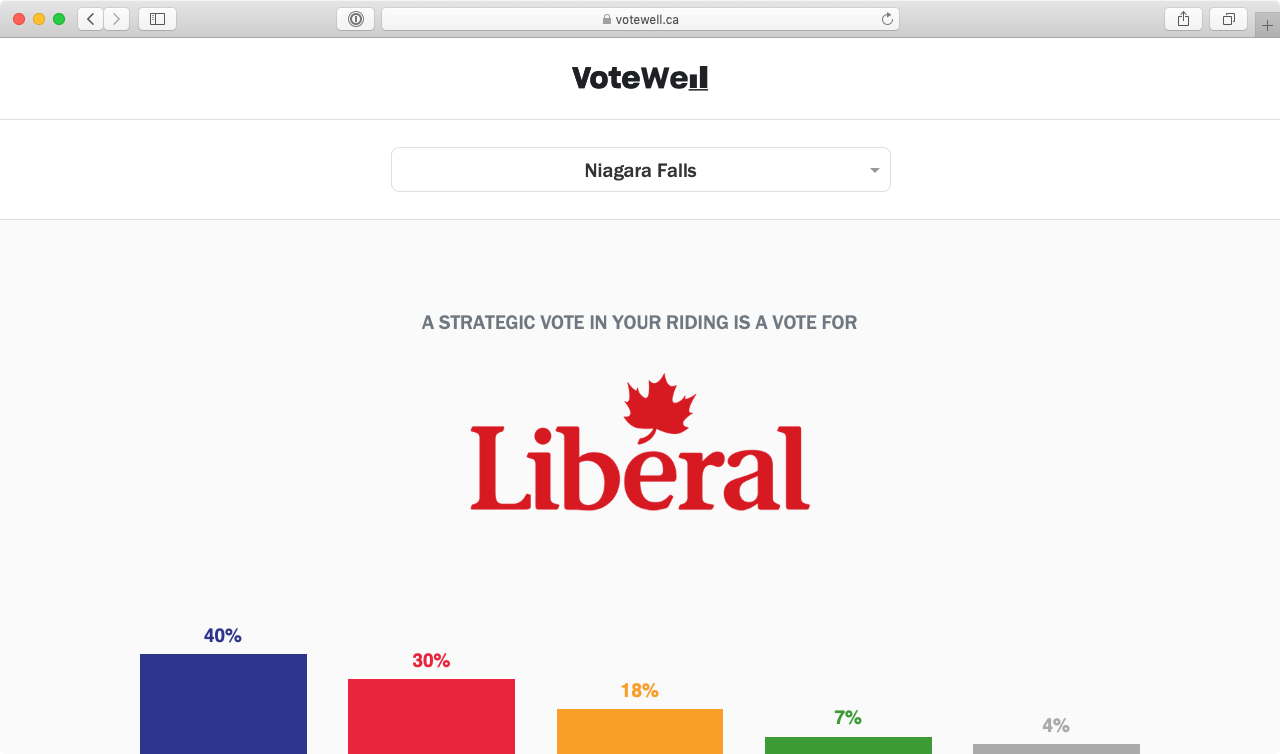
VoteWell
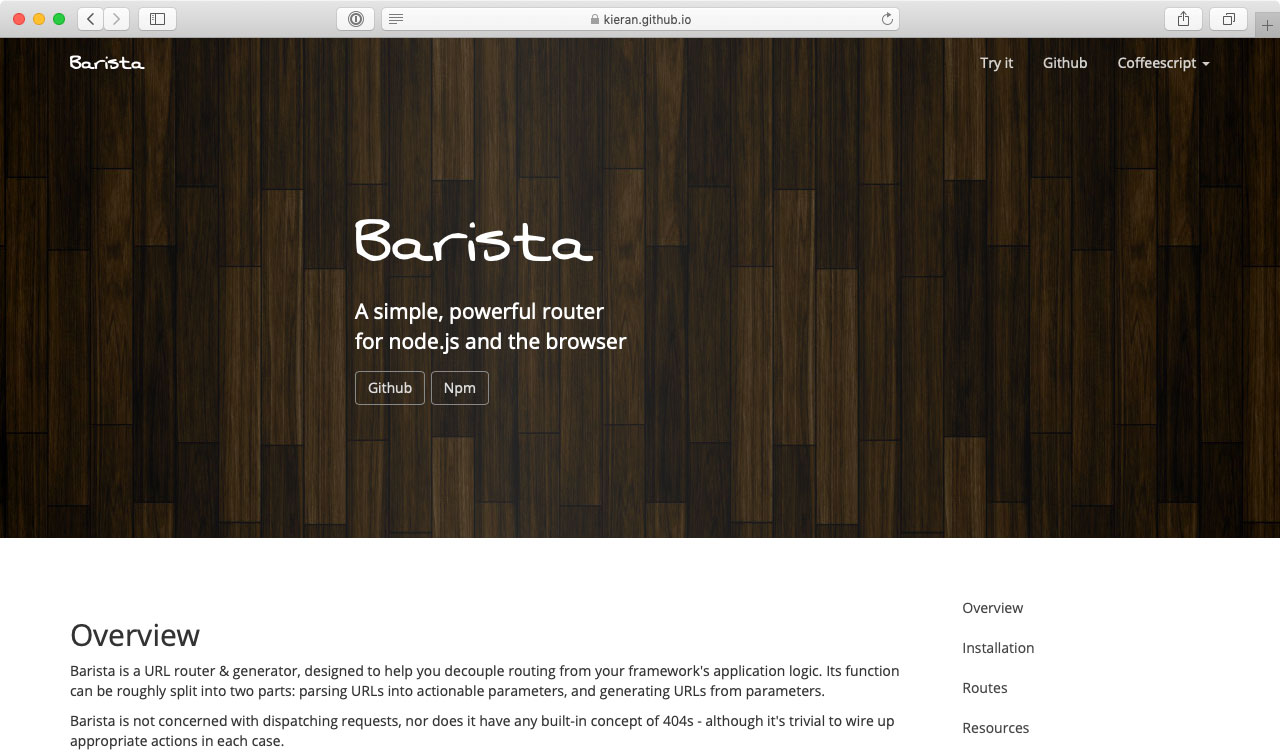
Barista
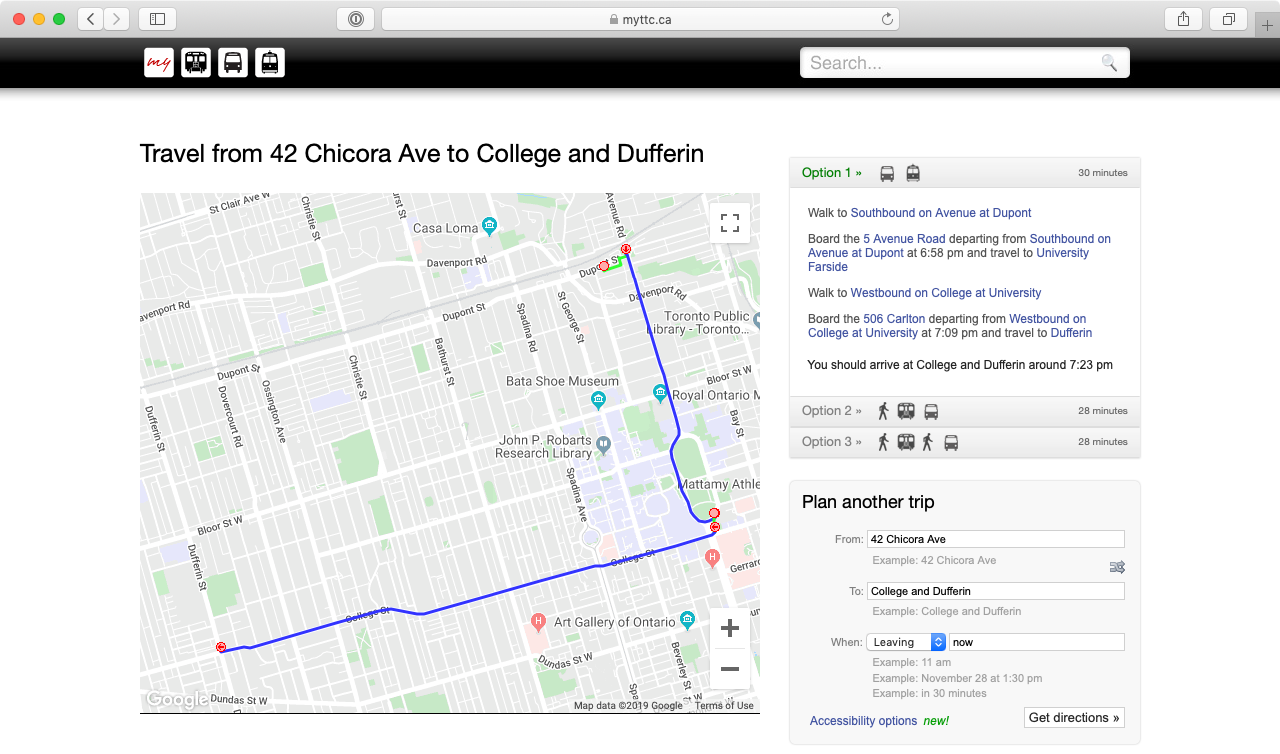
MyTTC